亲爱的社区小伙伴们,我们很高兴地宣布,Apache Doris 在 2022 年 7 月 14 日迎来 1.1 Release 版本的正式发布!这是 Apache Doris 正式从 Apache 孵化器毕业后并成为 Apache 顶级项目后发布的第一个 Release 版本。在 1.1 版本中,有 90 位 Contributor 为 Apache Doris 提交了超过 450 项优化和修复,感谢每一个让 Apache Doris 变得更好的你!
在 1.1 版本中,我们实现了计算层和存储层的全面向量化、正式将向量化执行引擎作为稳定功能进行全面启用,所有查询默认通过向量化执行引擎来执行,性能较之前版本有 3-5 倍的巨大提升;增加了直接访问 Apache Iceberg 外部表的能力,支持对 Doris 和 Iceberg 中的数据进行联邦查询,扩展了 Apache Doris 在数据湖上的分析能力;在原有的 LZ4 基础上增加了 ZSTD 压缩算法,进一步提升了数据压缩率;修复了诸多之前版本存在的性能与稳定性问题,使系统稳定性得到大幅提升。欢迎大家下载使用。
下载链接
GitHub 地址:https://github.com/apache/incubator-doris
下载地址:https://doris.apache.org/downloads/downloads.html
源码地址:https://github.com/apache/doris/releases/tag/1.1.0-rc05
升级说明
向量化执行引擎默认开启
在 Apache Doris 1.0 版本中,我们引入了向量化执行引擎作为实验性功能。用户需要在执行 SQL 查询手工开启,通过 set batch_size = 4096 和 set enable_vectorized_engine = true 配置 session 变量来开启向量化执行引擎。
在 1.1 版本中,我们正式将向量化执行引擎作为稳定功能进行了全面启用,session 变量enable_vectorized_engine 默认设置为 true,无需用户手工开启,所有查询默认通过向量化执行引擎来执行。
BE 二进制文件更名
BE 二进制文件从原有的 palo_be 更名为 doris_be ,如果您以前依赖进程名称进行集群管理和其他操作,请注意修改相关脚本。
Segment 存储格式升级
Apache Doris 早期版本的存储格式为 Segment V1,在 0.12 版本中我们实现了新的存储格式 Segment V2 ,引入了 Bitmap 索引、内存表、Page Cache、字典压缩以及延迟物化等诸多特性。从 0.13 版本开始,新建表的默认存储格式为 Segment V2,与此同时也保留了对 Segment V1 格式的兼容。
为了保证代码结构的可维护性、降低冗余历史代码带来的额外学习及开发成本,我们决定从下一个版本起不再支持 Segment v1 存储格式,预计在 Apache Doris 1.2 版本中将删除这部分代码,还请所有仍在使用 Segment V1 存储格式的用户务必在 1.1 版本中完成数据格式的转换,操作手册请参考以下链接:
https://doris.apache.org/zh-CN/1.0/administrator-guide/segment-v2-usage.html
正常升级
正常升级操作请按照官网上的集群升级文档进行滚动升级即可。
https://doris.apache.org/zh-CN/docs/admin-manual/cluster-management/upgrade.html
重要功能
在某些场景中(例如日志分析类场景),用户可能无法找到一个合适的分桶键来避免数据倾斜,因此需要由系统提供额外的分布方式来解决数据倾斜的问题。
因此通过在建表时可以不指定具体分桶键,选择使用随机分布对数据进行分桶DISTRIBUTED BY random BUCKET number,数据导入时将会随机写入单个 Tablet ,以减少加载过程中的数据扇出,并减少资源开销、提升系统稳定性。
Iceberg 外部表为 Apache Doris 提供了直接访问存储在 Iceberg 数据的能力。通过 Iceberg 外部表可以实现对本地存储和 Iceberg 存储的数据进行联邦查询,省去繁琐的数据加载工作、简化数据分析的系统架构,并进行更复杂的分析操作。
在 1.1 版本中,Apache Doris 支持了创建 Iceberg 外部表并查询数据,并支持通过 REFRESH 命令实现 Iceberg 数据库中所有表 Schema 的自动同步。
目前 Apache Doris 中数据压缩方法是系统统一指定的,默认为 LZ4。针对部分对数据存储成本敏感的场景,例如日志类场景,原有的数据压缩率需求无法得到满足。
在 1.1 版本中,用户建表时可以在表属性中设置"compression"="zstd" 将压缩方法指定为 ZSTD。在 25GB 1.1 亿行的文本日志测试数据中,最高获得了近 10 倍的压缩率、较原有压缩率提升了 53%,从磁盘读取数据并进行解压缩的速度提升了 30% 。
功能优化
更全面的向量化支持
在 1.1 版本中,我们实现了计算层和存储层的全面向量化,包括:
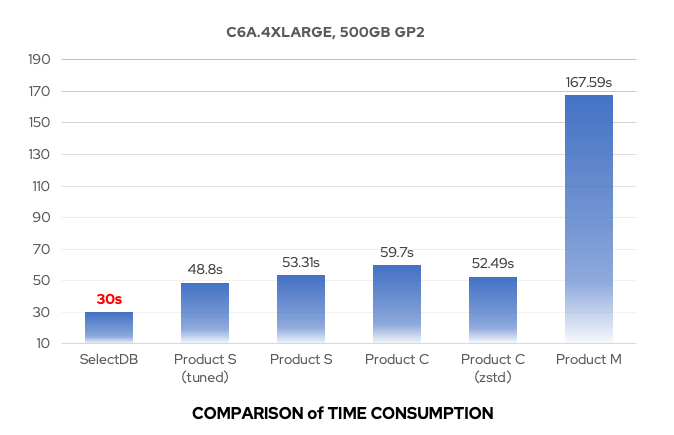
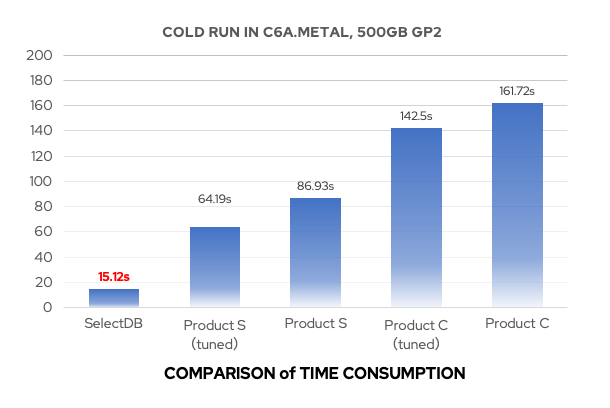
我们对 Apache Doris 1.1 版本与 0.15 版本分别在 SSB 和 TPC-H 标准测试数据集上进行了性能测试:
- 在 SSB 测试数据集的全部 13 个 SQL 上,1.1 版本均优于 0.15 版本,整体性能约提升了 3 倍,解决了 1.0 版本中存在的部分场景性能劣化问题;
- 在 TPC-H 测试数据集的全部 22 个 SQL 上,1.1 版本均优于 0.15 版本,整体性能约提升了 4.5 倍,部分场景性能达到了十余倍的提升;
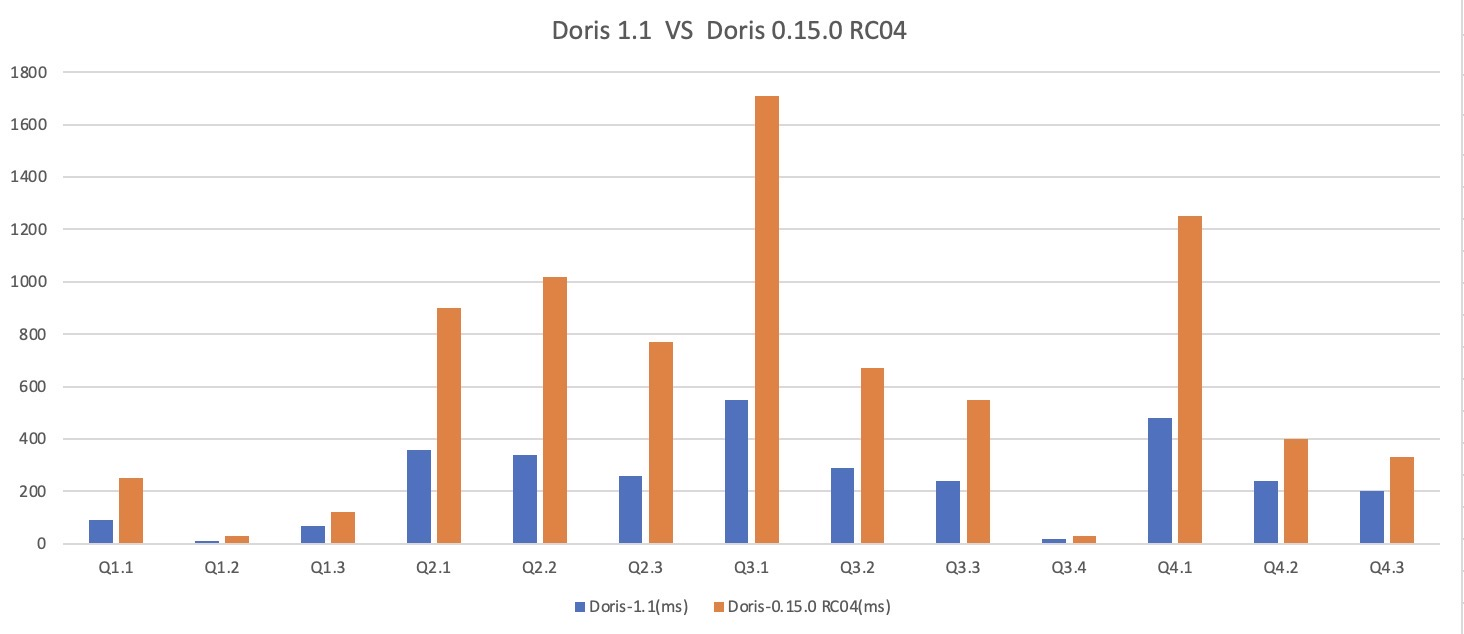
SSB 测试数据集
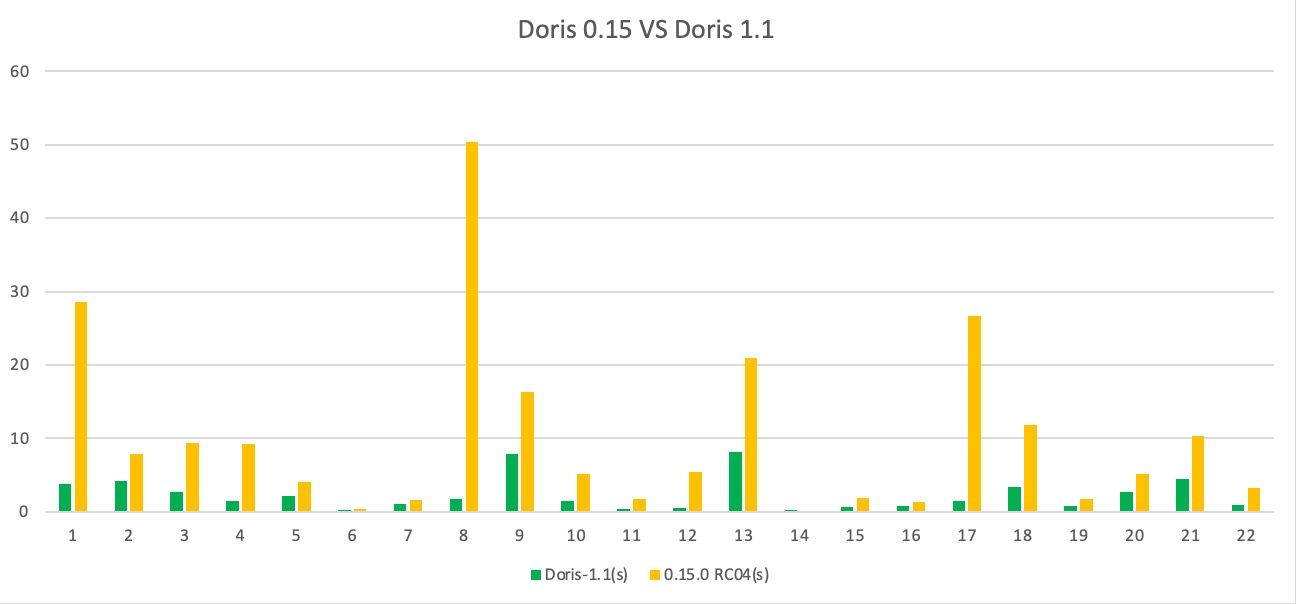
TPC-H 测试数据集
性能测试报告:
https://doris.apache.org/zh-CN/docs/benchmark/ssb.html
https://doris.apache.org/zh-CN/docs/benchmark/tpch.html
Compaction 逻辑优化与实时性保证 #10153
在 Apache Doris 中每次 Commit 都会产生一个数据版本,在高并发写入场景下,容易出现因数据版本过多且 Compaction 不及时而导致的 -235 错误,同时查询性能也会随之下降。
在 1.1 版本中我们引入了 QuickCompaction,增加了主动触发式的 Compaction 检查,在数据版本增加的时候主动触发 Compaction,同时通过提升分片元信息扫描的能力,快速发现数据版本过多的分片并触发 Compaction。通过主动式触发加被动式扫描的方式,彻底解决数据合并的实时性问题。
同时,针对高频的小文件 Cumulative Compaction,实现了 Compaction 任务的调度隔离,防止重量级的 Base Compaction 对新增数据的合并造成影响。
最后,针对小文件合并,优化了小文件合并的策略,采用梯度合并的方式,每次参与合并的文件都属于同一个数据量级,防止大小差别很大的版本进行合并,逐渐有层次的合并,减少单个文件参与合并的次数,能够大幅地节省系统的 CPU 消耗。
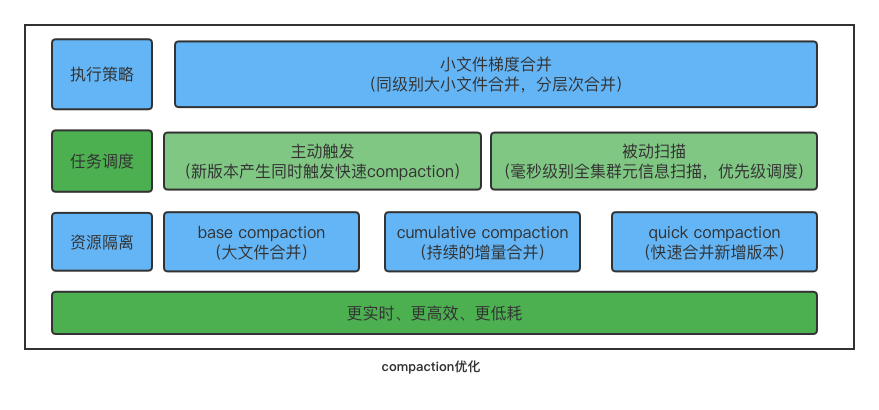
在数据上游维持每秒 10w 的写入频率时(20 个并发写入任务、每个作业 5000 行、 Checkpoint 间隔 1s),1.1 版本表现如下:
- 数据快速合并:Tablet 数据版本维持在 50 以下,Compaction Score 稳定。相较于之前版本高并发写入时频繁出现的 -235 问题,Compaction 合并效率有 10 倍以上的提升。
- CPU 资源消耗显著降低:针对小文件 Compaction 进行了策略优化,在上述高并发写入场景下,CPU 资源消耗降低 25% ;
- 查询耗时稳定:提升了数据整体有序性,大幅降低查询耗时的波动性,高并发写入时的查询耗时与仅查询时持平,查询性能较之前版本有 3-4 倍提升。
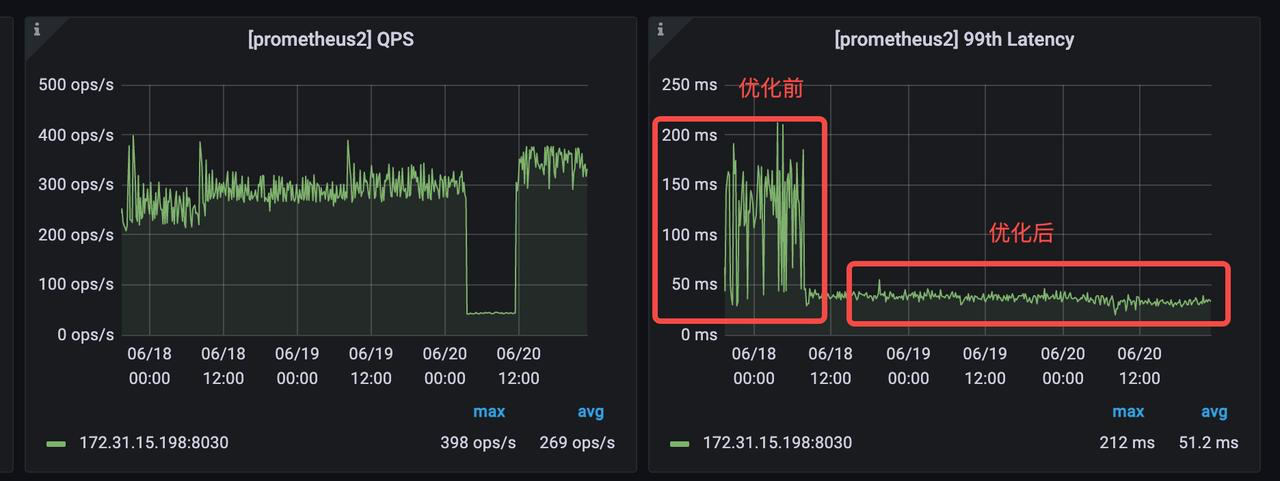
Parquet 和 ORC 文件的读取效率优化 #9472
通过调整 Arrow 参数,利用 Arrow 的多线程读取能力来加速 Arrow 对每个 row_group 的读取,并修改成 SPSC 模型,通过预取来降低等待网络的代价。优化前后对 Parquet 文件导入的性能有 4 ~ 5 倍的提升。
通过对元数据检查点后生成的 image 文件进行双重检查和保留历史 image 文件的功能,解决了 image 文件错误导致的元数据损坏问题。
Bug 修复
修复由于缺少数据版本而无法查询数据的问题。(严重)#9267 #9266
问题描述:failed to initialize storage reader. tablet=924991.xxxx, res=-214, backend=xxxx
该问题是在版本 1.0 中引入的,可能会导致多个副本的数据版本丢失。
解决了资源隔离对加载任务的资源使用限制无效的问题(中等)#9492
在 1.1 版本中, Broker Load 和 Routine Load 将使用具有指定资源标记的 BE 节点进行加载。
修复使用 HTTP BRPC 超过 2GB 传输网络数据包导致数据传输错误的问题(中等)#9770
在以前的版本中,当通过 BRPC 在后端之间传输的数据超过 2GB 时,可能会导致数据传输错误。
禁用 Mini Load
Mini Load 与 Stream Load 的导入实现方式完全一致,都是通过 HTTP 协议提交和传输数据,在导入功能支持上 Stream Load 更加完备。
在 1.1 版本中,默认情况下 Mini Load 接口 /_load 将处于禁用状态,请统一使用 Stream Load 来替换 Mini Load。您也可以通过关闭 FE 配置项 disable_mini_load 来重新启用 Mini Load 接口。在版本 1.2 中,将彻底删除 Mini Load 。
完全禁用 SegmentV1 存储格式
在 1.1 版本中将不再允许新创建 SegmentV1 存储格式的数据,现有数据仍可以继续正常访问。
您可以使用 ADMIN SHOW TABLET STORAGE FORMAT 语句检查集群中是否仍然存在 SegmentV1 格式的数据,如果存在请务必通过数据转换命令转换为 SegmentV2。
在 Apache Doris 1.2 版本中不再支持对 Segment V1 数据的访问,同时 Segment V1 代码将被彻底删除。
限制 String 类型的最大长度 #8567
String 类型是 Apache Doris 在 0.15 版本中引入的新数据类型,在过去 String 类型的最大长度允许为 2GB。
在 1.1 版本中,我们将 String 类型的最大长度限制为 1 MB,超过此长度的字符串无法再写入,同时不再支持将 String 类型用作表的 Key 列、分区列以及分桶列。
已写入的字符串类型可以正常访问。
修复 fastjson 相关漏洞 #9763
对 Canal 版本进行更新以修复 fastjson 安全漏洞
添加了 ADMIN DIAGNOSE TABLET 命令 #8839
通过 ADMIN DIAGNOSE TABLET tablet_id 命令可以快速诊断指定 Tablet 的问题。
下载使用
下载链接
http://doris.apache.org/zh-CN/downloads/downloads.html
升级说明
您可以从 Apache Doris 1.0 Release 版本和 1.0.x 发行版本升级到 1.1 Release 版本,升级过程请官网参考文档。如果您当前是 0.15 Release 版本或 0.15.x 发行版本,可跳过 1.0 版本直接升级至 1.1。
http://doris.apache.org/zh-CN/installing/upgrade.html
意见反馈
如果您遇到任何使用上的问题,欢迎随时通过 GitHub Discussion 论坛或者 Dev 邮件组与我们取得联系。
GitHub 论坛:https://github.com/apache/incubator-doris/discussions
Dev 邮件组:dev@doris.apache.org
Apache Doris 1.1 Release 版本的发布离不开所有社区用户的支持,在此向所有参与版本设计、开发、测试、讨论的社区贡献者们表示感谢,他们分别是:
@adonis0147
@airborne12
@amosbird
@aopangzi
@arthuryangcs
@awakeljw
@BePPPower
@BiteTheDDDDt
@bridgeDream
@caiconghui
@cambyzju
@ccoffline
@chenlinzhong
@daikon12
@DarvenDuan
@dataalive
@dataroaring
@deardeng
@Doris-Extras
@emerkfu
@EmmyMiao87
@englefly
@Gabriel39
@GoGoWen
@gtchaos
@HappenLee
@hello-stephen
@Henry2SS
@hewei-nju
@hf200012
@jacktengg
@jackwener
@Jibing-Li
@JNSimba
@kangshisen
@Kikyou1997
@kylinmac
@Lchangliang
@leo65535
@liaoxin01
@liutang123
@lovingfeel
@luozenglin
@luwei16
@luzhijing
@mklzl
@morningman
@morrySnow
@nextdreamblue
@Nivane
@pengxiangyu
@qidaye
@qzsee
@SaintBacchus
@SleepyBear96
@smallhibiscus
@spaces-X
@stalary
@starocean999
@steadyBoy
@SWJTU-ZhangLei
@Tanya-W
@tarepanda1024
@tianhui5
@Userwhite
@wangbo
@wangyf0555
@weizuo93
@whutpencil
@wsjz
@wunan1210
@xiaokang
@xinyiZzz
@xlwh
@xy720
@yangzhg
@Yankee24
@yiguolei
@yinzhijian
@yixiutt
@zbtzbtzbt
@zenoyang
@zhangstar333
@zhangyifan27
@zhannngchen
@zhengshengjun
@zhengshiJ
@zingdle
@zuochunwei
@zy-kkk